TLDR; I can not add any setting to the options.pool settings because this inherently blocks Strapi from connecting to my postgres db with ECONNREFUSED
Today morning my Strapi Service, hosted on Render.com went down due to the following knex error:
KnexTimeoutError: Knex: Timeout acquiring a connection. The pool is probably full. Are you missing a .transacting(trx) call?
After a couple of min the server healed itself but I already had the issue 2 weeks ago and I attribute it to the fact that given the amount of traffic there might be too few connection pools open. Render allows 97 but Strapi’s default settings have 10.
So my rational was to increase the max pool size to 30 and see if it improves the issue.
According to Strapi v3 there’s an options.pool setting where I should be easily able to adjust the settings.
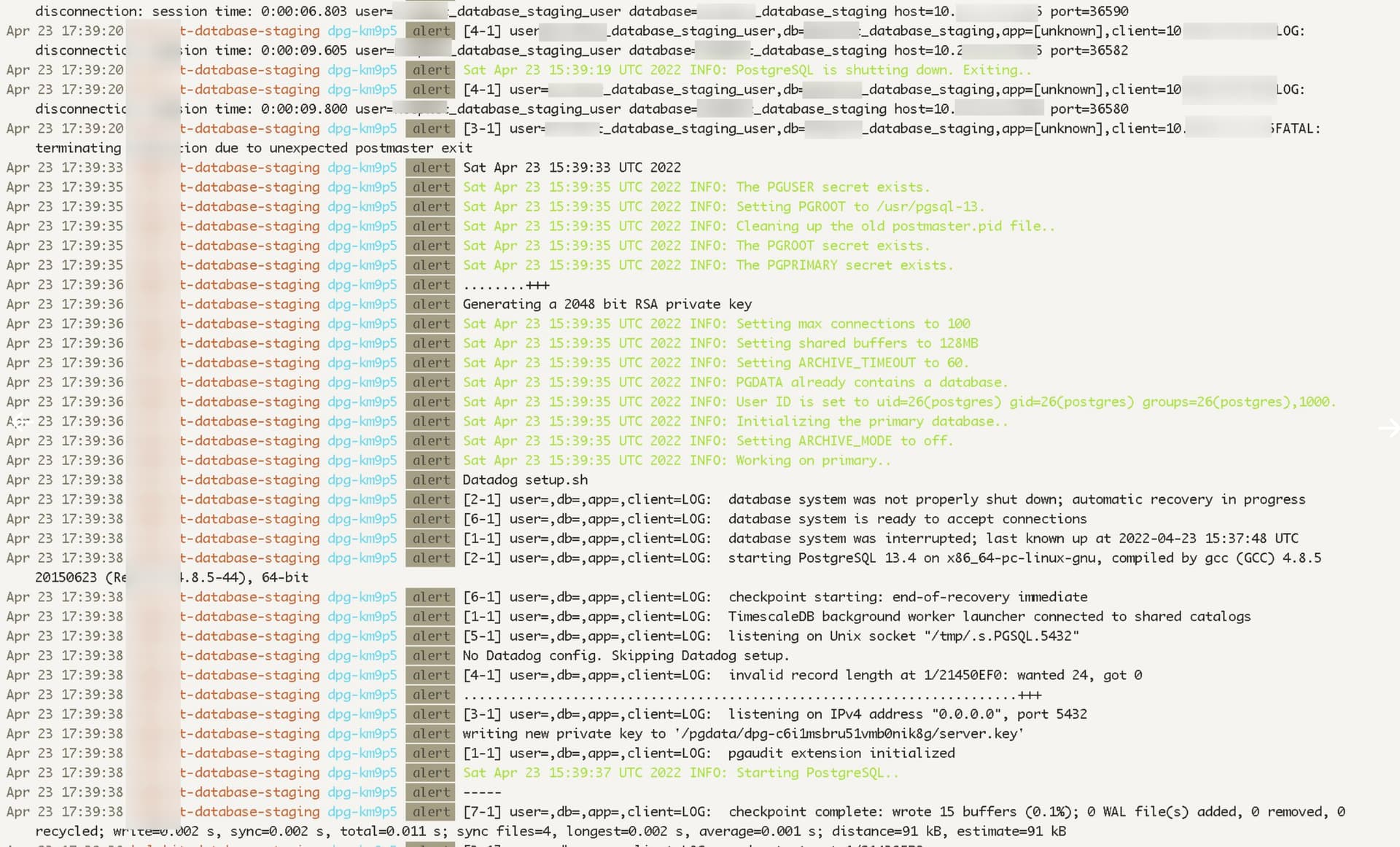
As soon as the deploy is successfully built and Strapi wants to start I get the “ECONNREFUSED” error indicating that there might be a problem connecting to the postgres db:
And in fact, whenever there’s something in the options.pool object Postgres seems to do a restart?! which inherently causes the connections issues (I think)
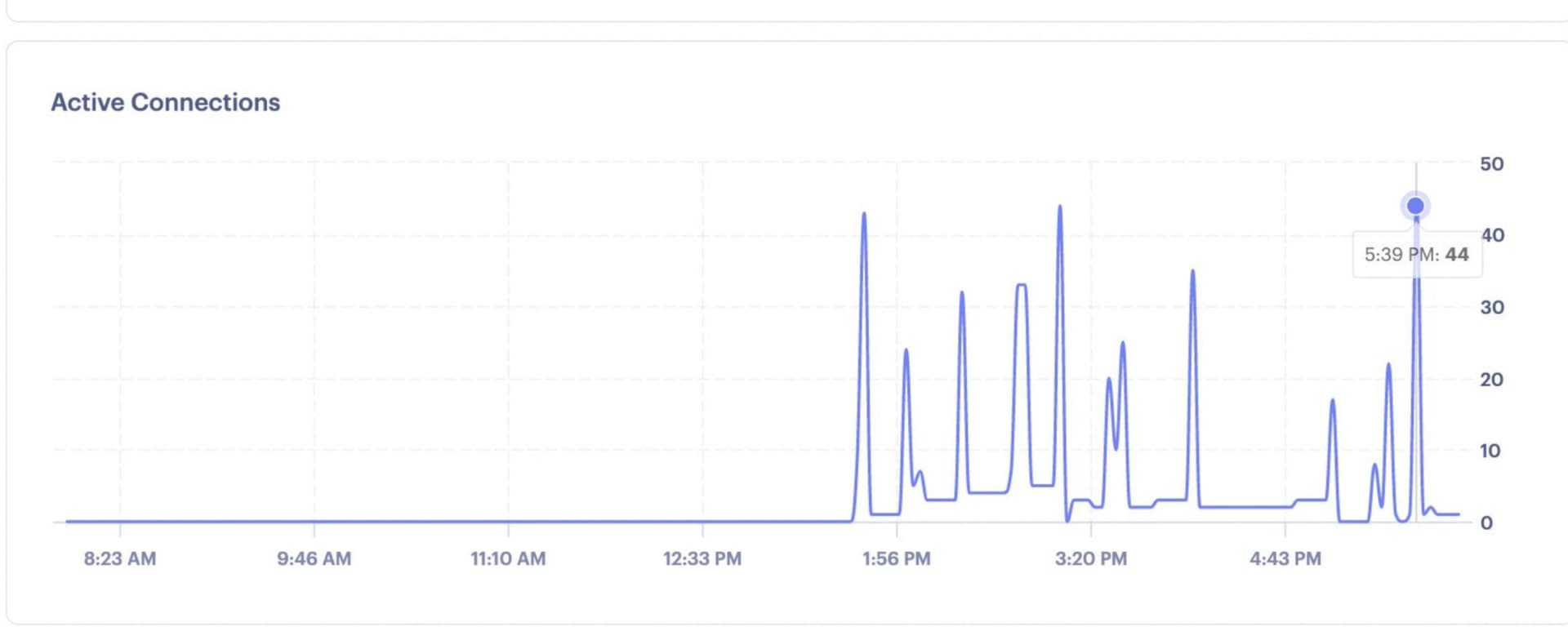
I first tried it with (min: 2, max: 30) then with (min:0, max:30 + all the options below) all basically lead to the same issue… In addition, I also noticed that the connection activity spikes as soon as I deploy the new update.
I temporary increased the Node resources to a very big plan (4 CPU, 8GB RAM) which did not really help (besides that the backend was quite fast of course).
So the node server can not really be the problem I guess…
Next I will try to increase my Postgres Plan (I use the smallest one right now. The one you have, too). Maybe this one is the bottleneck caused by the shared CPU and the low RAM?
Its unfortunately not possible to downgrade a database. Thats the reason I did not try this until now…
Another thought I had was that maybe the underlying service from render could cause issues when deploying a version which requires database updates.
Render sites and services come with fully managed and free TLS certificates, and Render services are automatically restarted if they become unresponsive.
So could it be, that there is something like pm2 under the hood at render com and when we deploy a database content model change the new version manipulates the database structure but the old running instance which is still active (because 0 downtime deployments) runs into troubles with the new database and crashes? Then restarts itself and applys old content model changes again to the database? This is just a gues without beeing able to test or confirm it…
Right now i experienced that if I restart/redeploy often enough at some (random) redeploy iteration everything is suddenly fine and strapi runs with the new version.
Yes I totally agree with your thoughts of the 0 downtime redeploy issue being the ultimate issue in this case. It seems like the update in Strapi database settings always causes the Render database to restart but perhaps due to traffic or something else it gets a huge spike in connections and despite a longer waitOut time it still throws a ECONNREFUSED.
I confirm, after doing the deployment like 3-4 times in a row it suddenly works. However, this is absolutely not acceptable for me running a critical production server. I can’t deploy and hope that after 3 deployment failures it all of a sudden works… until I have to push a new update or the server restarts for an unknown reason and causes the whole problem over again.
I already reached out to Render and they told me the issue is on Strapi’s side. I feel extremely stuck and really need to update my pool size soon but there’s no way for me to do.
nevertheless it only happens when a content model change is required (changed / added / deleted fields/content types). Other changes (controller logic, strapi updates, etc.) are fine and the server starts quite fast without any issues.
My emergency workaround (when redeploy does not help at all) right now is:
“suspend” the strapi node instance. (No idea how fast this is, never needed to do this workaround so far). But it is needed - else it restarts and re-applys old code and crashes I guess.
do a pg_dump of the production database (I always do this before deploying ofc.).
Then start strapi with the production db locally. This will apply all database structure changes without any issues quite fast.
Then do pg_restore back to production.
Push strapi code to github
reactivate node server.
I want to say I am absolutely not a fan of this but if nothing else works this should do the job…
I will let you know once I tested the bigger database plan on render. Maybe this just “fixes” the issues.
Would appreciate your further experiences with this issue, too, if you have some.
it only happens when a content model change is required
I don’t agree with this as for me - even without changing content models - the bug causing issue is when I change the options.pool object in the database.js file. As you can see above in the image even just adding for example min: 2, max: 30 causes this issue. So for me it seems that modifying the pool settings directly correlates with the bug I am experiencing. Without that everything works just fine so far.
Hi @Dominik Yesterday I tried to increase the render database plan (Bigger Plan for 20$/month). It did not change anything.
IMHO this is definitely NOT an issue with server resources but with render infrastructure itself. I am experiencing different issues there. The one with broken deployments, then with random connection loses to database (even with the bigger payed plan one) after 10 minutes of idle or something.
I created a setup now on digitalocean. Was a smooth experience and (so far!) I am not experiencing any of those connection losses…
Heroku same issue. Happend after i added a new field to a content type. Any change to the shcema of any content type ends up in knex error. That is a huge issue in general. Adding data to existing schema works all the time. Changing the schema creates the problem. Anyone has any idea of how to fix that?
Hmm that’s looks exactly like the problem I am experiencing! Unfortunately, I am still on v3 so I hope I can port over the fix once it gets finally merged…
Oh wow… I thought this problem only started manifesting with v.4 and v.3 used a different connector than Knex, so not that many reported the issue yet…
So guys here is some update from my deployment setup.
I had huge issues on render.com with my setup. I got the knex issue, after some idle time the server lost connection to the database and needed to reboot, … So I increased database and node ressources to very high specs. Without any improvement.
So I switched to digitalocean app platform to check if this an issue of render. (Setup is as easy as with render)
… Well, yes, it is an issue with render… (At least for me)
I am using the following setup now on digitalocean:
Web service: $20.00/mo – Basic 2 GB RAM | 1 vCPU x 1
Dev Database: 7$/mo 512 MB RAM, Shared CPU, 1 GB Disk
Even with this “low specs” (I bought a lot bigger package on render) I am not facing any of the above mentioned issues.
Changing database models → no knex issues
No idle connection issues
I have no idea what the issue is at render.com.
But I wasted a lot of time trying to fix the render hosting with pool settings and stuff and it only caused frustration.
TLDR: If anyone has the same issues i highly recommend to benefit of my painful experience, skip render and just use digitalocean (or some other hosting provider)